BDA420
UDF, Joins, and RDDs
Summary
UDF
Joining and Merging
RDDs:
→ Introduction
→ Operations
→ Conversions
Data for this Lecture
Data for this Lecture
We will use the users, drivers_data, and health_insurance datasets in this lecture
You can download them from Blackboard
udf
Introduction
User defined functions, UDF, are used to extend the Framework
Allow you to apply custom logic that isn't natively supported by Spark's built-in functions
UDFs can be slower than Spark native functions because Spark treats them as black-box functions, preventing internal optimizations
Registering an UDF
To use an UDF, you need to:
→ Create a Python function
→ Register this function using the udf() method
There are three ways to use the UDF method
functionNameUDF = udf(lambda inputs: functionName(inputs), outputType() )
Registering an UDF
There are three ways to use the UDF method:
Simple:
funcNameUDF = udf(funcName, outputType())Using a lambda function:
funcNameUDF = udf(lambda inputs: funcName(inputs), outputType())Using a decorator
@udf(outputType())
funcDefinitionUDF Example 1
from pyspark.sql.types import StringType
def categorize_age(age):
if age < 18:
return "Minor"
elif age < 40:
return "Adult"
else:
return "Senior"
categorize_age_udf = udf(categorize_age, StringType())
#categorize_age_udf = udf(lambda age: categorize_age(age), \
# StringType())
#@udf(StringType())
#def categorize_age_udf(age):
# if age < 18:
# return "Minor"
# elif age < 40:
# return "Adult"
# else:
# return "Senior"
display(df.withColumn("age_category", \
categorize_age_udf(df["age"])))UDF Example 2
def format_name(name):
return name.capitalize()
format_name_udf = udf(format_name, StringType())
display(df.withColumn("formatted_name", \
format_name_udf(df["name"]).drop("name"))UDF Example 2
def format_name(name):
return name.capitalize()
format_name_udf = udf(format_name, StringType())
display(df.withColumn("formatted_name", \
format_name_udf(df["name"]).drop("name"))UDF Example 3
def city_initials(city):
words = city.split()
if len(words) > 1:
return "".join([word[0].upper() for word in words])
else:
return words[0][:2].capitalize()
city_initials_udf = udf(city_initials, StringType())
display(df.withColumn("city_initials", \
city_initials_udf(df["city"]))Joining and Merging
Joining DataFrames
The join() method can be used to join two or more DataFrames
It adds more columns to your data
It performs all traditional SQL join operations such as: inner,
outer, left, right, etc.
SQL Joins
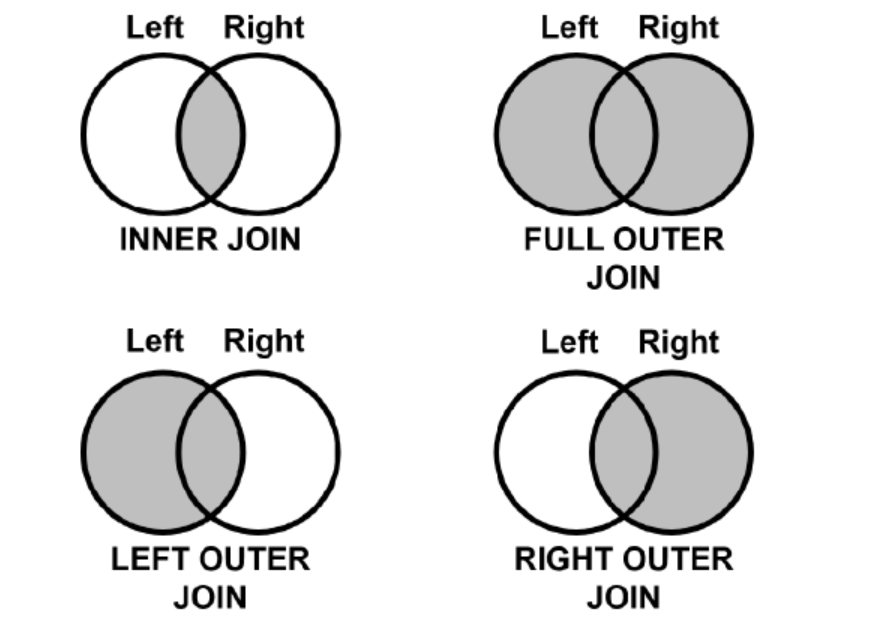
Joining DataFrames
When joining dataframes, attention needs to be taken to avoid ending up with extra columns
For inner joins, one can drop duplicated columns prior to join
For other joins, one might need to rename columns, use coalesce, and drop columns after join
Inner Join Example
path = "/FileStore/tables/drivers_data.csv"
df2 = spark.read.csv(path, header=True, inferSchema=True)
display(df2)
path = "/FileStore/tables/health_insurance.csv"
df3 = spark.read.csv(path, header=True, inferSchema=True)
display(df3)
df4 = df3.drop("first_name", "last_name", "dob")
df5 = df2.join(df4, on="email", how="inner")
display(df5)
Outer Join Example
from pyspark.sql.functions import coalesce
df2a = df2.withColumnRenamed("first_name", "first_name_lic")\
.withColumnRenamed("last_name", "last_name_lic")\
.withColumnRenamed("dob", "dob_license")
df3a = df3.withColumnRenamed("first_name", "first_name_in")\
.withColumnRenamed("last_name", "last_name_in")
.withColumnRenamed("dob", "dob_insurance")
df5 = df2a.join(df3a, on="email", how="outer")
df5 = df5.withColumn("first_name", \
coalesce(df5["first_name_lic"], df5["first_name_in"]))\
.withColumn("last_name",
coalesce(df5["last_name_lic"], df5["last_name_in"]))\
.withColumn("dob",
coalesce(df5["dob_lic"], df5["dob_in"]))
df5 = df5.drop("first_name_lic", "first_name_in")\
.drop("last_name_lic", "last_name_in")\
.drop("dob_lic", "dob_in")
display(df5)
Merging DataFrames
The union() method can be used to merge DataFrames with same schema
Adds more rows to your data
To avoid duplicates, you can apply the distinct() method
Union Example 1
from pyspark.sql.types import *
schema = StructType([
StructField("id", IntegerType(), True),
StructField("name", StringType(), True),
StructField("age", IntegerType(), True)
])
data1 = [(1, "Alice", 25), (2, "Bob", 30), (3, "Charlie", 35)]
data2 = [(3, "Charlie", 35), (4, "David", 40)]
dfa = spark.createDataFrame(data1, schema=schema)
dfb = spark.createDataFrame(data2, schema=schema)
df_union = dfa.union(dfb)
display(df_union)
display(df_union.distinct())Merging DataFrames
If the schemas are not the same*, an error is returned
One can align the schemas prior to merging by:
→ adding empty columns
→ removing unnecessary columns
Afterwards, ensure that columns on both dataframes are in the same positions
Union Example 2
from pyspark.sql.functions import lit
schema1 = StructType([
StructField("id", IntegerType(), True),
StructField("name", StringType(), True),
StructField("age", IntegerType(), True)
])
schema2 = StructType([
StructField("id", IntegerType(), True),
StructField("name", StringType(), True),
StructField("salary", IntegerType(), True)
])
data1 = [(1, "Alice", 25), (2, "Bob", 30)]
data2 = [(3, "Charlie", 50000), (4, "David", 60000)]
dfa = spark.createDataFrame(data=data1, schema=schema1)
dfb = spark.createDataFrame(data=data2, schema=schema2)
dfa_aligned = dfa.withColumn("salary", lit(None))
dfb_aligned = dfb.withColumn("age", lit(None))
display(dfa_aligned)
display(dfb_aligned)
#ensures proper alignment
dfa_aligned = dfa_aligned.select("id", "name", "age", "salary")
dfb_aligned = dfb_aligned.select("id", "name", "age", "salary")
df_union = dfa_aligned.union(dfb_aligned)
display(df_union)RDDs Introduction
what are RDDs
Resilient Distributed Datasets - RDDs are at the heart of the Spark framework
An RDD is a read-only, fault-tolerant, partitioned collection of records
Spark provides several methods to operate on RDDs
Dataframes are built on top of RDDs - Impose an extra structure (columns)
Creating RDDs
RDDs can be created from files and from dataframes
They can also be created using Python lists and tuples with parallelize()
RDDs are not subscriptable (indexable)
This is because the data is distributed accross partitions, and no structure is imposed on RDDs
Accessing RDDs elements
Index operations, such as rddName[i] would fail
There are ways to obtain a subset RDD elements
.collect() is an action that returns a Python list with all RDD records
.take(N) is an action that returns a Python list with N RDD records
Creating RDDs
players =[["Vini", "Real Madrid", 23, "forward"], \
["Haaland", "Manchester City", 23], \
["Mbappe", "PSG", 25, "French"], \
["Salah", 31]]
players_rdd = spark.sparkContext.parallelize(players)
print(type(players_rdd))
#print(players_rdd[1]) #error
print(players_rdd.take(2))
print(players_rdd.collect())
print(players_rdd.count())Creating RDDs
RDDs can be created from text files with with textFile()
By default, each line of the text file will correspond to one record
path = "/FileStore/tables/frost.txt"
poem = spark.sparkContext.textFile(path)
print(poem.collect())
print(poem.count())RDD Operations
Map
map applies a transformation to all RDD records
Generally, this transformation is a lambda function
It always creates a new RDD with the same number of records as the original
words = poem.map(lambda line: line.split(" "))
print(words.collect())
print(words.count())flatMap
flatMap also applies a transformation to all RDD records
Its output can have a different number of records than the original
words = poem.flatMap(lambda line: line.split(" "))
print(words.collect())
print(poem.count())
print(words.count())Data
All remaining examples in this section will use an RDD, called rdd created from the personnel.csv file with the code below:
path = "/FileStore/tables/personnel.csv"
personnel = spark.sparkContext.textFile(path)
print(personnel.take(2))
personnel_split = personnel.map(lambda x: (x.split(",")))\
.map(lambda x: [*x[0:6], float(x[6])])
print(personnel_split.take(2))Filter
filter returns a new RDD with only the records that pass a given condition
print(personnel_split.count())
print(personnel_split.filter(lambda a: a[4] == "Ontario").count())
print(personnel_split.filter(lambda a: (a[4] == "Ontario") & \
(a[6] > 150000)).count())
print(personnel_split.filter(lambda a: (a[4] == "Ontario") & \
(a[6] > 150000)).take(5))sortBy
sortBy returns a new RDD with the sorted data
Lambda functions can be used to specify which element of the record to use for sorting
A True/False parameter can be given to specify ascending(T)/descending(F) order
personnel_sorted = personnel_split.sortBy(lambda a: a[6], False)
print(personnel_sorted.take(5))
personnel_sorted = personnel_split.sortBy(lambda a: a[6], True)
print(personnel_sorted.take(5))
reduce
reduce is an aggregate function that returns a value based on a recursive operation on all records
print(personnel_split.map(lambda x: x[6]).reduce(lambda x,y: x+y))
print(personnel_split.filter(lambda x: (x[4] == "Ontario"))\
.map(lambda x: x[6])\
.reduce(lambda x,y: x+y))
RDD Conversions
RDDs to DFs
RDDs can be converted to dataframes with the .toDF() method
By default, the column names will be _1, _2, _3, etc.
A list with columns names can be provided as an argument
df = personnel_split.toDF();
df = personnel_split.toDF(["first_name", "last_name", \
"email", "gender", "province", "dept", "salary"]);
display(df)RDDs to DFs (2)
createDataFrame() can also be used to create a DataFrame from an RDD
It takes two arguments, the data, an RDD, and the schema
RDDs to DFs (2)
from pyspark.sql.types import *
schema = StructType([
StructField("first_name", StringType(),True),
StructField("last_email", StringType(),True),
StructField("email", StringType(),True),
StructField("gender", StringType(),True),
StructField("province", StringType(),True),
StructField("dept", StringType(),True),
StructField("salary", DoubleType(),True)])
df = spark.createDataFrame(data=personnel_split, schema=schema)
display(df)
df.printSchema()DFs to RDDs
Dataframes can also be converted to RDDs
Requires the use of the rdd property
This actually returns a list of Row objects
new_rdd_row = df.rdd
print(type(new_rdd_row))
print(new_rdd_row.collect())DFs to RDDs (2)
Using .map(list) allows users to get a pipelined RDD, instead of a Row Object
Column names are lost, as RDDs do not have the same structure as DataFrames
new_rdd = df.rdd.map(list)
print(type(new_rdd))
print(new_rdd.collect())Reading Material
A Guide to Mastering PySpark UDFs