BDA420
Apache Spark
Summary
Spark in a Nutshell
Parallelism
Spark Architecture
Data Types
Transformations and Actions
Libraries
Pyspark
Spark in a Nutshell
What is Spark?
Analytics engine for large-scale data processing
It provides high-level APIs for programming clusters:
→ implicit data parallelism
→ fault tolerance
Programmable in: Java, Scala,
Python, and R
Goal
To create a framework optimized for fast iterative processing
Retain the scalability and fault tolerance of Hadoop
Avoid Hadoop's need to perform disk I/O operations for each step
Memory vs Disk
How to work with it?
- Install it or use an online service
- Write scripts using your preferred language
- Connect your scripts to a Spark kernel*
- Let Spark take care of optimization, parallelization, and fault tolerance
- PROFIT
What's next
Spark allows for optimized parallelization with fault tolerance
But, what is parallellization?
And, why do we need it?
Parallelism
How Computers Work
All processing happens at the CPU
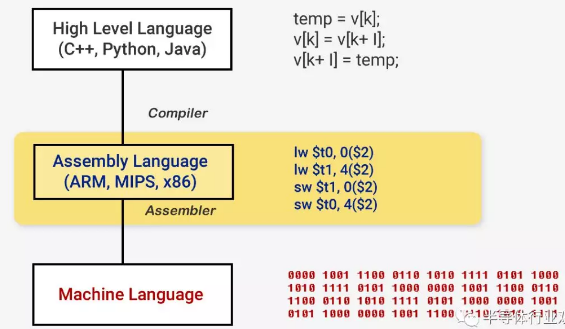
High-level languages → Assembly instructions
ADD, SUB, MUL,
DIV, CMP, AND, MOV, etc.
Each instruction takes one clock-cycle
How Computers Work
Historical Perspective
Clock Rates grew tremendously until the early 2000's
Power Consumption and overheating are preventing further advances
Solution: More CPUs!
Historical Perspective
The amount of RAM memory on computers also grew tremendously until the early 2000's
Quantum effects and power consumption are preventing more dense packing
Solution: More memory slots!
Types of Parallelism
A number of different parallel solutions were created
Laptops started to be dual-core or quad-core
Specialized hardware: GPUs, VLSI Chips, FPGAs, PlayStations, XBOX, etc.
Cluster Computing
Multi core
Each core runs a different task in parallel
The operating system manages tasks
Applications need to be designed for multiple cores
Specialized Hardware
Made to perform specific tasks
Great performance in highly parallel tasks
Applications need to be specifically designed for them
More complex than regular programming
Cluster Computing
Multiple regular computers working in coordination
Master-slave and peer to peer architectures
Supercomputers are clusters with thousands of CPUs
Applications need to be written using cluster frameworks
This is the methodology chosen by hadoop and spark
What's next
We now know that Spark achieves parallelism via cluster computing
Next we will delve into how does it do it
Spark Architecture
Technical Details
Written in the Scala language
Runs on a Java Virtual Machine (JVM) environment
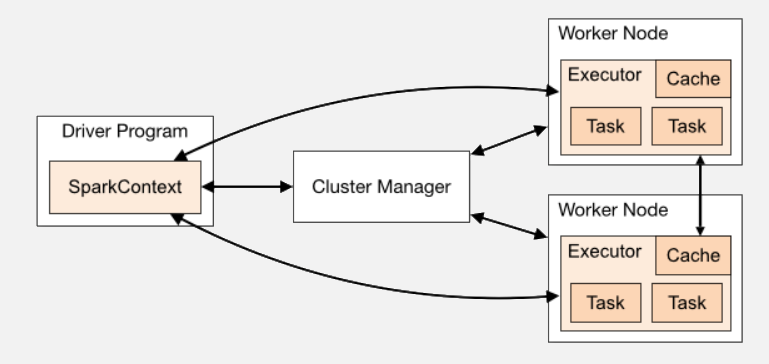
Uses a master-slave architecture:
→ A master (driver) node creates a SparkContext that communicates with a cluster manager
→ The cluster manager acquires executers in slave (worker) nodes
Cluster Management
Technical Details
Both the driver and the worker nodes run on JVMs
Each node needs its own JVM
Many cluster managers are available: Spark's built-in standalone, YARN, Mesos, and Kubernets
Technical Details
Nodes are normally located within the same local network
This ensures a low-latency and improves security
The framework allows for nodes to be located accross different networks
What's next
We now know how Spark works
Now we will see how does it work with data
Data
RDD
Spark introduced Resilient Distributed Datasets
Collection of immutable objects cached in memory
RDDs are partitioned accross a set of machines
Can be reused in multiple MapReduce-like operations
Fault tolerant
Spark in Action - RDD
from pyspark import SparkContext spark = SparkSession \ .builder \ .appName("BDA420") \ .config("spark.some.config.option", "some-value") \ .getOrCreate() path = "/FileStore/tables/frost.txt" poem = spark.sparkContext.textFile(path) print(poem.collect()) words = poem.map(lambda line: line.split(" ")) myList = words.collect() print(myList) print(len(myList))
from pyspark import SparkContext spark = SparkSession \ .builder \ .appName("BDA420") \ .config("spark.some.config.option", "some-value") \ .getOrCreate() path = "/FileStore/tables/frost.txt" poem = spark.sparkContext.textFile(path) print(poem.collect()) words = poem.map(lambda line: line.split(" ")) myList = words.collect() print(myList) print(len(myList))
from pyspark import SparkContext spark = SparkSession \ .builder \ .appName("BDA420") \ .config("spark.some.config.option", "some-value") \ .getOrCreate() path = "/FileStore/tables/frost.txt" poem = spark.sparkContext.textFile(path) print(poem.collect()) words = poem.map(lambda line: line.split(" ")) myList = words.collect() print(myList) print(len(myList))
from pyspark import SparkContext spark = SparkSession \ .builder \ .appName("BDA420") \ .config("spark.some.config.option", "some-value") \ .getOrCreate() path = "/FileStore/tables/frost.txt" poem = spark.sparkContext.textFile(path) print(poem.collect()) words = poem.map(lambda line: line.split(" ")) myList = words.collect() print(myList) print(len(myList))
DataFrames
An immutable distributed collection of data
Built on top of RDDs - Provides higher abstraction
Data is organized into named columns
Similar to Pandas' DataFrames
There are also DataSets for strongly typed languages (Java and
Scala)
Spark in Action - DataFrames
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName("BDA420") \ .config("spark.some.config.option", "some-value") \ .getOrCreate() path = "/FileStore/tables/grades.csv" data = spark.read.csv(path, header=True) data.show() data.filter(data['grades'] > 80).show()
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName("BDA420") \ .config("spark.some.config.option", "some-value") \ .getOrCreate() path = "/FileStore/tables/grades.csv" data = spark.read.csv(path, header=True) data.show() data.filter(data['grades'] > 80).show()
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName("BDA420") \ .config("spark.some.config.option", "some-value") \ .getOrCreate() path = "/FileStore/tables/grades.csv" data = spark.read.csv(path, header=True) data.show() data.filter(data['grades'] > 80).show()
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName("BDA420") \ .config("spark.some.config.option", "some-value") \ .getOrCreate() path = "/FileStore/tables/grades.csv" data = spark.read.csv(path, header=True) data.show() data.filter(data['grades'] > 80).show()
What's next
We now know how Spark sees data
Now we will see how it works with it
Transformations and Actions
Transformations
Transformations create new RDDs (or DataFrames) from an existing one
map, filter, and sort are
transformations
All transformations are lazy
Spark builds a graph with all transform operations and only apply them when an action is triggered
Lazy Evaluation

Actions
Actions return a value to the driver program after processing the RDDs (or DataFrames)
reduce, count, and save are actions
What's next
We now know how Spark works on data
Now we will briefly cover a number of libraries that allow it to work on many fields of data sciences
Libraries
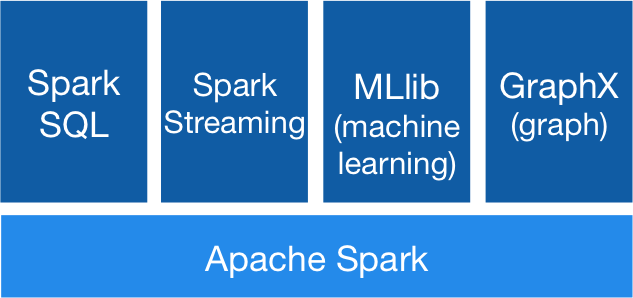
Core (Apache Spark)
Distributed execution engine
In charge of I/O functionality
Performs task dispatching
Handles fault recovery
SQL
Module designed to work with structured data
Allows the use of SQL queries
Implements a DataFrame structure
Streaming
Enables scalable processing of live data streams
Allows for data coming from multiple sources
Accepts diverse types of schemas
Machine Learning
Implements commonly used ML algorithms such as:
→ Collaborative Filtering
→ Classification
→ Regression
→ Clustering
GraphX
Module designed for graphs and graph-parallel computations
PySpark

PySpark is the Python API for Spark
Uses Py4J to allow Python code to dynamically access Java objects in a JVM
Reading Material
A Gentle Introduction to Spark (book)
Introduction to Spark (article)
What is Spark (video)