BDA420
Datetime Operations
Summary
Data for this Lecture
Date and Time Functions
Window Operations
Data for this Lecture
Data for this Lecture
We will use the accounts and covid19 datasets in this lecture
You can download it from Blackboard
Data for this Lecture
path = "/FileStore/tables/accounts.csv"
df = spark.read.csv(path, header=True, inferSchema=True)
df.printSchema()
display(df)
path = "/FileStore/tables/covid19.csv"
df2 = spark.read.csv(path, header=True, inferSchema=True)
df2.printSchema()
display(df2)Introduction
Date and Time Functions
Fields containing dates, times, and combined dates and times (timestamps) are very common
Hence, any data analytics framework needs to be able to properly handle such types
Spark provides multiple of functions to handle such fields: link
Data and Time Formats
There are multiple ways to represent the same date:
2025-02-04, 04-02-2025, 02/04/2025, and 04-Feb-2025 are just some ways to represent the same date
There are also multiple ways to represent a given time:
14:30:00, 2:30:00 PM, 9:30:00 EST, are just some ways to represent the same time
Data and Time Formats
Spark can handle dates and times in multiple formats
The default format for a date is: yyyy-MM-dd
The default format for a timestamp is: yyyy-MM-dd HH:mm:ss:SSSSSS
The time zone is, by default, assumed to be the UTC
Creating Time Fields
DateType
A DateType type is provided in Spark
Dates that are not in the default format might be stored as strings with inferSchema
Applying a schema without specifying the date format results in nulls
Example - WRONG
from pyspark.sql.types import *
schema = StructType([ \
StructField("first_name",StringType(),True), \
StructField("last_name",StringType(),True), \
StructField("email", StringType(), True), \
StructField("account_created", DateType(), True), \
StructField("last_access", DateType(), True), \
StructField("active", BooleanType(), True)
])
path = "/FileStore/tables/accounts.csv"
df = spark.read.csv(path, header=True, schema=schema)
display(accounts)Example - RIGHT
A dateFormat can be specified with option
from pyspark.sql.types import *
schema = StructType([ \
StructField("first_name",StringType(),True), \
StructField("last_name",StringType(),True), \
StructField("email", StringType(), True), \
StructField("account_created", DateType(), True), \
StructField("last_access", DateType(), True), \
StructField("active", BooleanType(), True)
])
path = "/FileStore/tables/accounts.csv"
df = spark.read.option("dateFormat","M/d/y").\
csv(path, header=True, schema=schema)
display(accounts)to_date
A StringType field can be converted to date with to_date
The second argument specifies the date format
from pyspark.sql.functions import to_date
path = "/FileStore/tables/accounts.csv"
df = spark.read.csv(path, header=True)
df.printSchema()
df = df.withColumn("last_access", \
to_date(df["last_access"],"M/d/y")).\
withColumn("account_created", \
to_date(df["account_created"],"M/d/y"))
df.printSchema()
display(df)Date Operations
Date Comparisons
You can compare dates with logical operators such as == (same date), > (older), or < (newer)
from pyspark.sql.functions import when, col
df = df.withColumn("single_use", \
when(col("last_access") == col("account_created"), True)\
.otherwise(False))
display(df)Date Component Extractions
You can extract date components such as day, month, year, day of the week, etc.
from pyspark.sql.functions import col, dayofmonth, \
dayofweek, dayofyear, month, year
display(df.withColumn("day", dayofmonth(col("last_access"))))
display(df.withColumn("day", dayofweek(col("last_access"))))
display(df.withColumn("day", dayofyear(col("last_access"))))
display(df.withColumn("month", month(col("last_access"))))
display(df.withColumn("year", year(col("last_access"))))Date Operations
We can add or subtract days or months
The current_date() function is widely used
from pyspark.sql.functions import \
current_date, datediff, months_between, round
display(df.withColumn("inactivity", \
current_date() - df["last_access"])) \\
display(df.withColumn("inactivity", \
datediff(current_date(), df["last_access"])))
display(df.withColumn("inactivity", \
round(months_between(current_date(), df["last_access"]))))Timestamps
to_timestamp
to_timestamp converts strings to timestamps
You can extract timestamp components such as hour, minute, seconds, etc.
from pyspark.sql.functions import \
col, hour, minute, second, to_timestamp
data = [
("2025-02-04 08:15:30",),
("2025-02-04 09:45:15",),
("2025-02-04 10:05:50",),
("2025-02-04 11:30:20",),
("2025-02-04 12:55:05",)
]
df2 = spark.createDataFrame(data, ["timestamp_str"])
df2 = df2.withColumn("timestamp", \
to_timestamp(col("timestamp_str"), "yyyy-MM-dd HH:mm:ss"))\
.withColumn("hour", hour(col("timestamp")))\
.withColumn("minute", minute(col("timestamp")))\
.withColumn("second", second(col("timestamp")))
display(df2)
df2.printSchema()Timestamp Extractions
To extract the entire time component of the time stamp, you can use date_format.
from pyspark.sql.functions import col, to_timestamp, date_format
data = [
("2025-02-04 08:15:30",),
("2025-02-04 09:45:15",),
("2025-02-04 10:05:50",),
("2025-02-04 11:30:20",),
("2025-02-04 12:55:05",)
]
df2 = spark.createDataFrame(data, ["timestamp_str"])
df2 = df2.withColumn("timestamp", \
to_timestamp(col("timestamp_str"), "yyyy-MM-dd HH:mm:ss"))
display(df2.withColumn("time_only",
date_format(col("timestamp"), "HH:mm:ss")))Time Zones
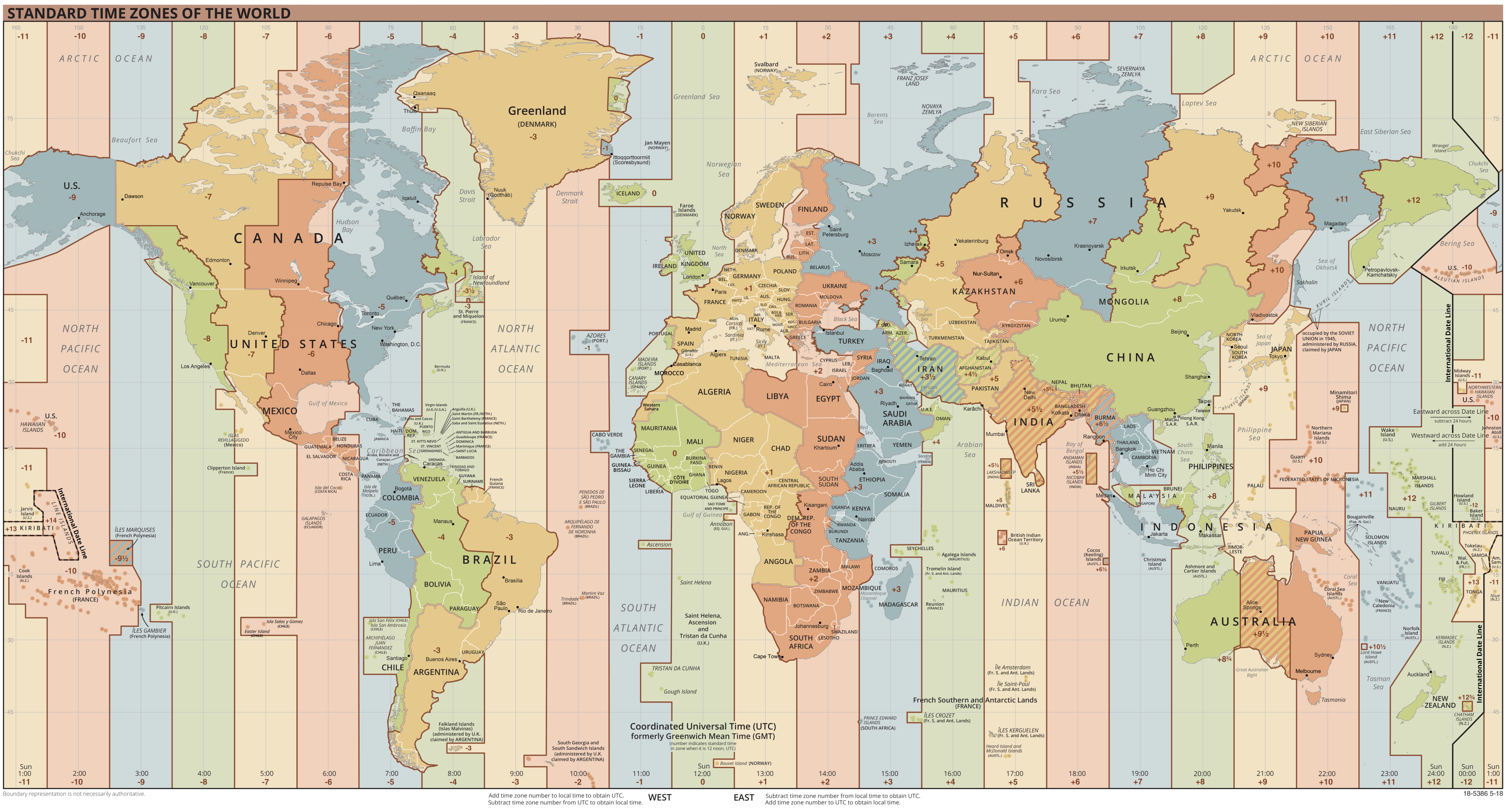
To_utc_timestamp
By default, Spark assumes the UTC as a time zone
The to_utc_timestamp can set local times to the UTC time
from pyspark.sql.functions import to_utc_timestamp
df2 = df2.withColumn("utc_timestamp", \
to_utc_timestamp("timestamp", 'EST'))
display(df2)Windows Introduction
Windows Introduction
Before we cover windows operations, lets review the types of operations that we have already covered:
→ Row Operations
→ GroupedData Operations
Row Operations
Performed on individual records and produce individual results:
String operations: lower, upper, length, etc.
Datetime operations: year, month, etc.
Math Functions: round, sqrt, abs, etc.
Grouped Data Operations
Performed on grouped data and produce a single result for each group
groupBy reduces the dataset by grouping rows and returning a groupedData object
Aggregates are calculated on groupedData: count, sum, max, etc.
Window Operations
Window operations calculate a return value for every input row of a table based on a group of rows, called a frame (window).
Very useful to calculate moving averages, creating rankings, and analytical functions
Window Specifications
WindowSpec
To run windows operations, the frame (window) needs to be specified
In Spark, windows are defined by a WindowSpec object
WindowSpec defines which rows to include in the frame (window) associated with a given input row
WindowSpec objects are created using the Window class
WindowSpec
To create a WindowSpec, the Window class needs to know the type of:
→ Partition: partitionBy
→ Ordering: orderBy
→ Frame: rowsBetween and rangeBetween
Note that you don't have to define all three for every window. Some windows use only one
WindowSpec Examples
from pyspark.sql.window import Window
windowSpec = Window.partitionBy("columnName")\
.orderBy("another columnName")
windowSpec = Window.partitionBy("columnName")\
.orderBy("another columnName")\
.rowsBetween(-3, 3)
windowSpec = Window.orderBy("columnName")partitionby
partitionBy defines which records are in the same partition
Takes one or more column names as arguments
If not defined, all records belong to the same partition
orderby
orderBy specifies the position or order of the records
Takes one or more column names as arguments
If not defined, no ordering is imposed
To use descending order, instead of ascending: col("COL_NAME").desc()
rowsbetween
rowsBetween defines a moving window around each current row
Takes as arguments integers representing the start and end of the window
rowsBetween(-2,2) would create a window of five records: two before, the current one, and two after
rangebetween
rangeBetween defines a moving window around the value of each current row
Takes as arguments numbers representing the value offsets from the value of the current row
rangeBetween(-100,100) would create a window contaning all records: up to one hundred below, and up to one hundred over the value of the current row
Window Functions
Introduction
Now that we know how to specify frames (windows)...
... we can use them in different types of operations:
Calculating moving averages
Creating rankings
Obtaining Analytical functions
Moving Averages
Frequently used to smoothing the data
Do not require the frame (window) to be ordered
Can use either rowsBetween() or rangeBetween()
Moving Average example
from pyspark.sql.functions import avg, max, min
windowSpec = Window.partitionBy("pruid").rowsBetween(-3,0)
display(df.withColumn("mean", \
avg("numtotal_last7").over(windowSpec)))
#display(df.withColumn("min", \
# min("numtotal_last7").over(windowSpec)))
#display(df.withColumn("max", \
# max("numtotal_last7").over(windowSpec)))Ranking Functions
Compare individual records against other records
They require the window to be ordered
Include: row_number, rank, dense_rank, and percent_rank
Ranking Functions Example
from pyspark.sql.window import Window
from pyspark.sql.functions import row_number, rank, \
dense_rank, percent_rank, col
#windowSpec = Window.partitionBy("pruid")\
# .orderBy("numtotal_last7")
windowSpec = Window.partitionBy("pruid")\
.orderBy(col("numtotal_last7").desc())
display(df.withColumn("row_number",
row_number().over(windowSpec)))
display(df.withColumn("row_number",
row_number().over(windowSpec))\
.filter(col("row_number") < 2))
#display(df.withColumn("dense_rank_number", \
# dense_rank().over(windowSpec)))
#display(df.withColumn("percent_rank_number", \
# percent_rank().over(windowSpec)))Analytical Functions
Analytical functions on individual records against other records
They require the window to be ordered
cume_dist, lead, lag
Analytical Functions Example
from pyspark.sql.functions import cume_dist, lag, lead
windowSpec = Window.partitionBy("pruid")\
.orderBy("numtotal_last7")
display(df.withColumn("cdf",
cume_dist().over(windowSpec)))
windowSpec = Window.partitionBy("pruid")\
.orderBy("date")
display(df.withColumn("previous week",
lag("numtotal_last7", 1).over(windowSpec))\
.withColumn("next week",
lead("numtotal_last7",1).over(windowSpec)))